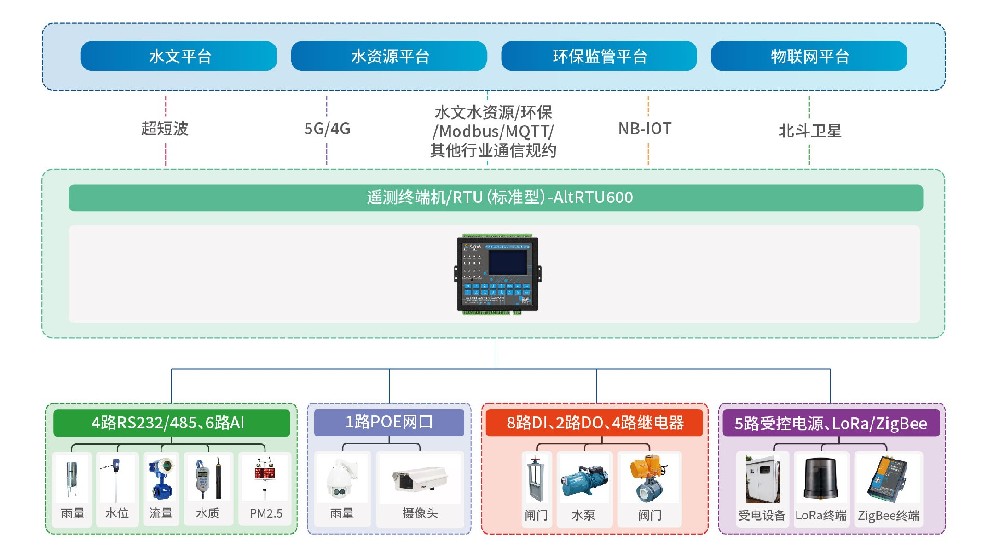

雙5G邊緣計算網關/工業CPE-AR7091G/GK
AR7091G/GK——基于5G/4G/3G/2G、WiFi、虛擬專網等技術開發的工業物聯網邊緣網關/CPE。產品采用高性能的工業級32位通信處理器和工業級無線模塊,以嵌入式操作系統為軟件支撐平臺,可同時連接串口設備、以太網設備和 WiFi 設備, 支持內部Flash和外擴Micro SD卡存儲數據,能滿足工業現場通信的需求。

 愛陸通節日動態:中秋博趣,好運連連!
愛陸通節日動態:中秋博趣,好運連連!
 分布式網關與集中式網關的區別與對比
分布式網關與集中式網關的區別與對比
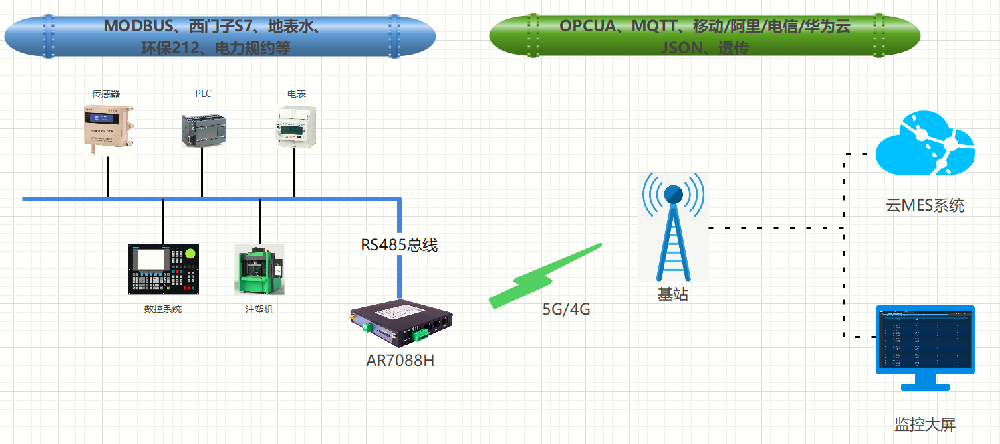
 集中式DTU通信解決方案-智能配網
集中式DTU通信解決方案-智能配網
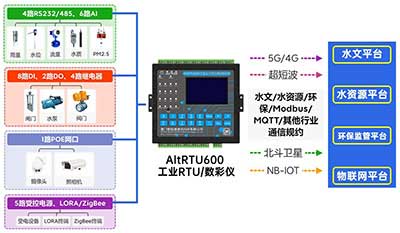 5G視頻RTU 視頻數采儀 數據采集傳輸儀
5G視頻RTU 視頻數采儀 數據采集傳輸儀
很多應用層協議都有HeartBeat機制,通常是客戶端每隔一小段時間向服務器發送一個數據包,通知服務器自己仍然在線,并傳輸一些可能必要的數據。使用心跳包的典型協議是IM,比如QQ/MSN/飛信等協議。
心跳包之所以叫心跳包是因為:它像心跳一樣每隔固定時間發一次,以此來告訴服務器,這個客戶端還活著。事實上這是為了保持長連接,至于這個包的內容,是沒有什么特別規定的,不過一般都是很小的包,或者只包含包頭的一個空包。
在TCP的機制里面,本身是存在有心跳包的機制的,也就是TCP的選項:SO_KEEPALIVE。系統默認是設置的2小時的心跳頻率。但是它檢查不到機器斷電、網線拔出、防火墻這些斷線。而且邏輯層處理斷線可能也不是那么好處理。一般,如果只是用于保活還是可以的。
心跳包一般來說都是在邏輯層發送空的echo包來實現的。下一個定時器,在一定時間間隔下發送一個空包給客戶端,然后客戶端反饋一個同樣的空包回來,服務器如果在一定時間內收不到客戶端發送過來的反饋包,那就只有認定說掉線了。
其實,要判定掉線,只需要send或者recv一下,如果結果為零,則為掉線。但是,在長連接下,有可能很長一段時間都沒有數據往來。理論上說,這個連接是一直保持連接的,但是實際情況中,如果中間節點出現什么故障是難以知道的。更要命的是,有的節點(防火墻)會自動把一定時間之內沒有數據交互的連接給斷掉。在這個時候,就需要我們的心跳包了,用于維持長連接,保活。
在獲知了斷線之后,服務器邏輯可能需要做一些事情,比如斷線后的數據清理呀,重新連接呀……當然,這個自然是要由邏輯層根據需求去做了。
總的來說,心跳包主要也就是用于長連接的保活和斷線處理。一般的應用下,判定時間在30-40秒比較不錯。如果實在要求高,那就在6-9秒。

心跳包的發送,通常有兩種技術
方法1:應用層自己實現的心跳包
由應用程序自己發送心跳包來檢測連接是否正常,大致的方法是:服務器在一個 Timer事件中定時 向客戶端發送一個短小精悍的數據包,然后啟動一個低級別的線程,在該線程中不斷檢測客戶端的回應, 如果在一定時間內沒有收到客戶端的回應,即認為客戶端已經掉線;同樣,如果客戶端在一定時間內沒 有收到服務器的心跳包,則認為連接不可用。
方法2:TCP的KeepAlive保活機制
因為要考慮到一個服務器通常會連接多個客戶端,因此由用戶在應用層自己實現心跳包,代碼較多 且稍顯復雜,而利用TCP/IP協議層為內置的KeepAlive功能來實現心跳功能則簡單得多。 不論是服務端還是客戶端,一方開啟KeepAlive功能后,就會自動在規定時間內向對方發送心跳包, 而另一方在收到心跳包后就會自動回復,以告訴對方我仍然在線。 因為開啟KeepAlive功能需要消耗額外的寬帶和流量,所以TCP協議層默認并不開啟KeepAlive功 能,盡管這微不足道,但在按流量計費的環境下增加了費用,另一方面,KeepAlive設置不合理時可能會 因為短暫的網絡波動而斷開健康的TCP連接。并且,默認的KeepAlive超時需要7,200,000 MilliSeconds, 即2小時,探測次數為5次。對于很多服務端應用程序來說,2小時的空閑時間太長。
因此,我們需要手工開啟KeepAlive功能并設置合理的KeepAlive參數。 心跳檢測步驟:
1客戶端每隔一個時間間隔發生一個探測包給服務器
2客戶端發包時啟動一個超時定時器
3服務器端接收到檢測包,應該回應一個包
4如果客戶機收到服務器的應答包,則說明服務器正常,刪除超時定時器
5如果客戶端的超時定時器超時,依然沒有收到應答包,則說明服務器掛了